Erst einmal vielen Dank für die ausführliche Analyse!

Überprüfe bitte an deinen Clients, ...
- ... ob sie jeweils (mindestens) über eine globale IPv6-Adresse verfügen, die mit "2a01:41e" beginnt, und ...
- ... ob sie jeweils über ein IPv6-Standardgateway verfügen, das der linklokalen (fe80...) IPv6-Adresse des LAN-Interface deines Routers entspricht.
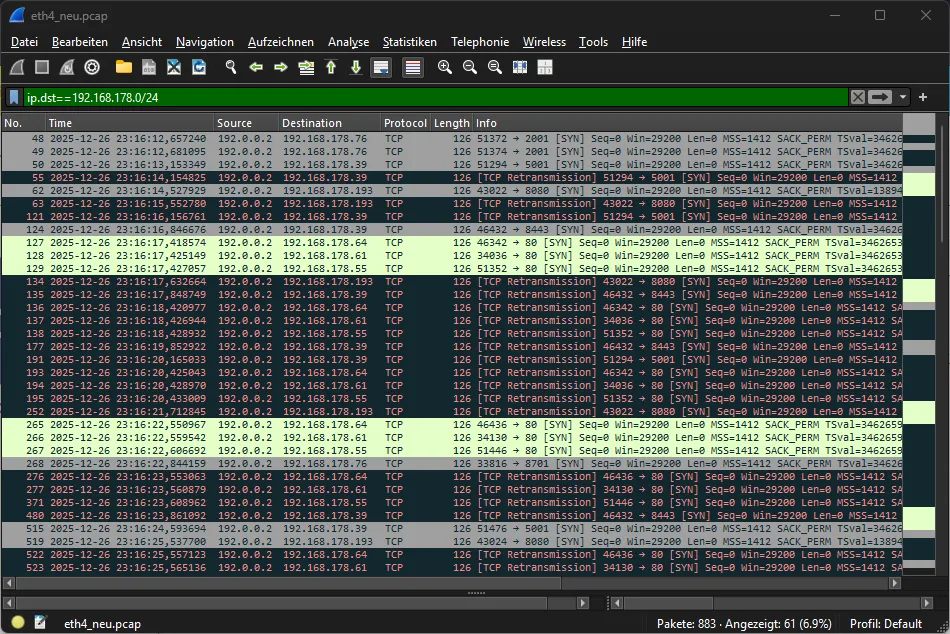
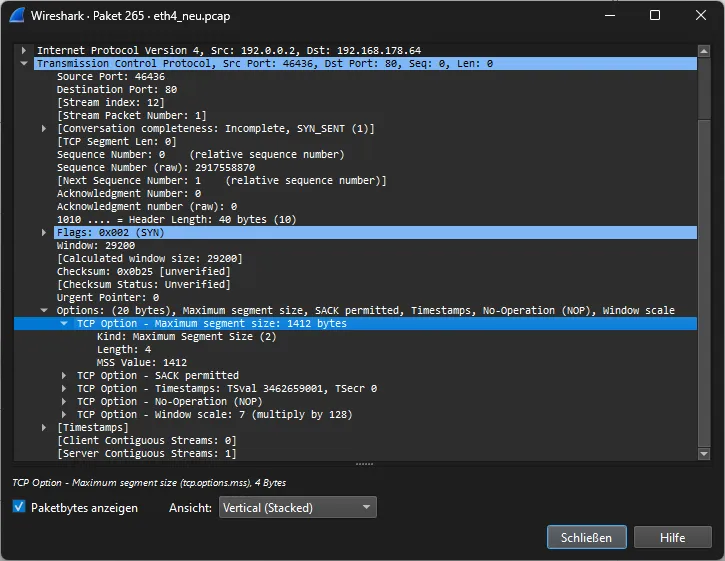
Diese beiden Punkte habe ich jetzt gelöst, die einzelnen VLANs zeigen jetzt die externe IPv6-Adresse an:

Bei den VLANs kann ich folgende Einstellungen bezgl. IPv6 vornehmen. Da kann ich nicht herausfinden, was richtig ist oder ob das wie eingestellt passt:
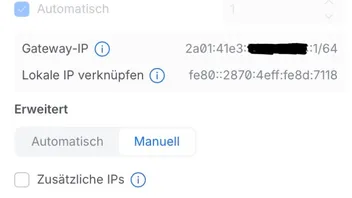
Und bei der WAN-Verbindung gibt es folgende IPv6-Einstellungen:
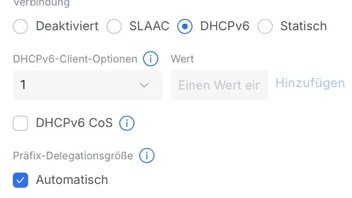
Da ich meine VLANs erst noch umorganisieren muss, konnte ich die Konfiguration nur rudimentär testen. So wie es aussieht, läuft es jedoch noch immer nicht ohne Probleme.